In brief and simple, I’m trying to understand PHY implementation in 5G.
Why do we use LDPC PHY encoder & polar encoder & coding block encoder?
Why all these three encoders in 5G?
What is the reasons for using three types and not only LDPC (lets say only polar encoder)?
Admin note: this post was updated with image below.
Ldpc is used for shared channel and polar is used for control channel
There are many reasons:
One such important reason is that Polar codes are extremely complex, as compared to LDPC, in terms of decoding.
For the case of control channels the control information to be transmitted is low and hence the number of possible control messages are low.
This can help in reducing the decoding complexity.
In Polar codes you need to first form the polarized channels considering the channel statistics and then decide which are the frozen bits.
This needs almost perfect CSI to be know at the transmitter, which is a overhead, when compared with LDPC codes, which doesn’t need any CSI.
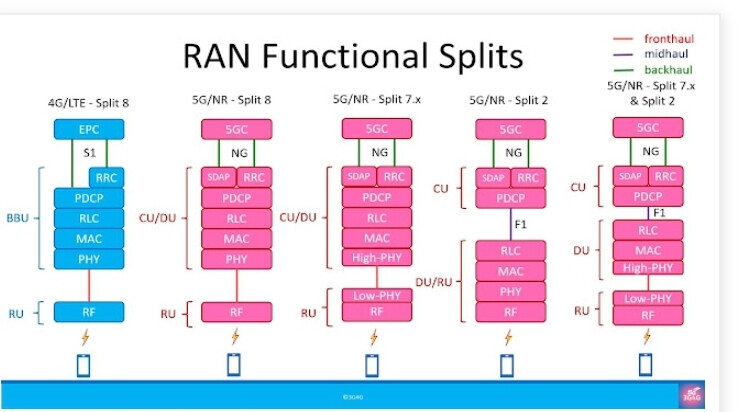
It’s true that the “RAN functional split” options are defined to have multiple options to separate L2 and L1 functionality between the CU, DU and RU. But this doesn’t really answer the question why.
The reason for having these options is, simply put, to enable more specialized use-cases. For example, having more processing blocks on the RU means that latency will decrease because the processing is done closer to the user. On the other hand, this makes the RU more complex, which in turn affects the power consumption, size, weight and cost of the unit.
If functionality in concentrated more on the other side (CU), it means more benefits in terms of centralizing, i.e. load balancing and resource sharing between different CUs, the other side of the coin being increased latency etc.
Having a single split just wouldn’t work for all use cases