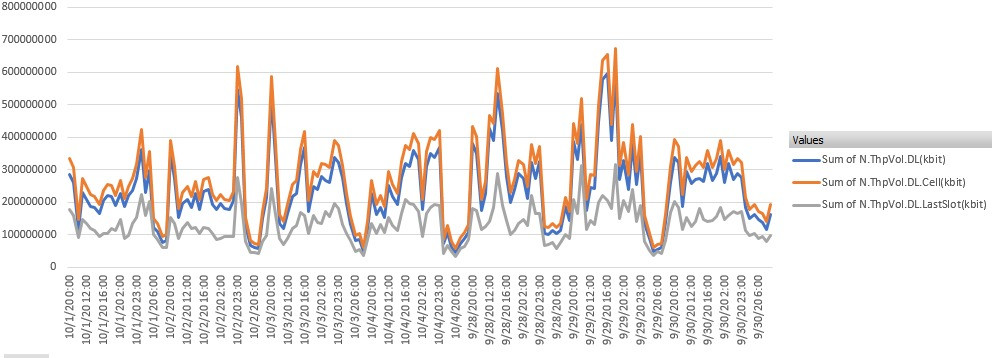
Other cell have also important data on last slot.
I mean high traffic on last slot.
You can check in your network too.
This means reduced traffic coming from chit-chat data like facebook messenger, whataspp, email, linkedin, etc.
Not heavy downloaders.
Indeed, this could be a solution, network wide to compare which one is closer to reality.
In last slot is almost 50% of volume of traffic, how can we remove it from formula even if 3GPP recommends this?
Cell has no capacity issue as MU-MIMO is active with 8 layers.
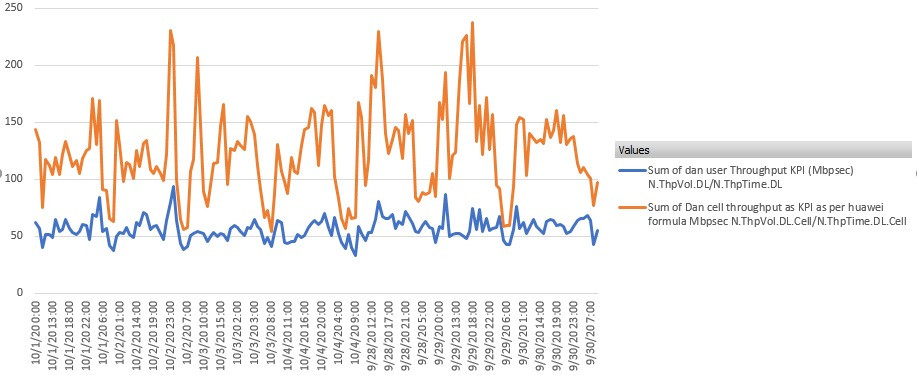
As one can not user throughput is somehow constant in time which is normal it depends on RF conditions of users.
If users are static throughput will be the same,more or less.
Just to add every vendor having different algorithm for throughput calculation.
Once we done comparison and seen Huawei no 1.
Nokia 2 Mbps for cell where huawei showing 9 Mbps.
Ericsson just scheduled users in one go.
Effectively less time.
User Throughput inversely proportional to time.
So main focus is that how vendor algorithm can shorten time.
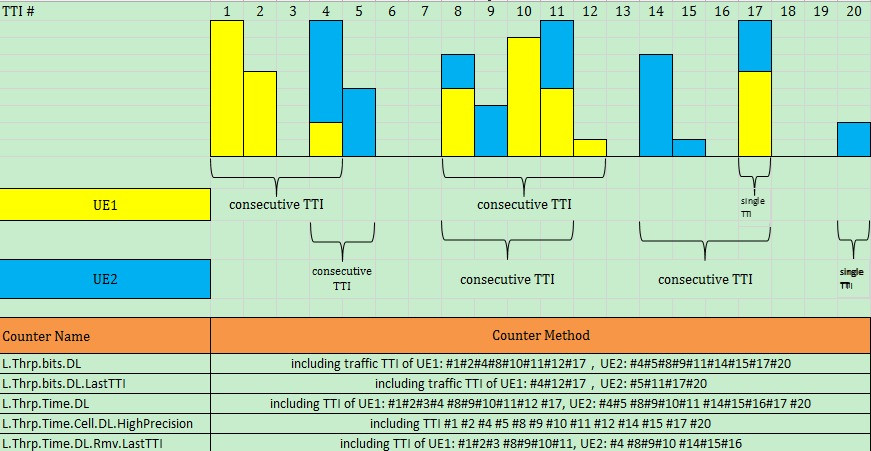
I am still not able to find counter for number of slots that scheduler sent data in DL.
Having that one it will be easy to calculate users scheduled per slot and much more.
But where to get that counter from?
Last TTI is usually underutilized.
So if the % of last TTI is high, it is typical to have Cell Throughput lower than User Throughput.
Example:
A single user in the cell that utilizes 2 TTI (1000 bits in 1st TTI and 100 bits in last TTI)
Then User Throughput is 1 Mbps while Cell Throughput is 550 kbps.
Removing last TTI is recommended by 3GPP.
Unfortunately it favors cell edge since cell center user may empty buffer in one TTI (BW dependent and packet size dependent).
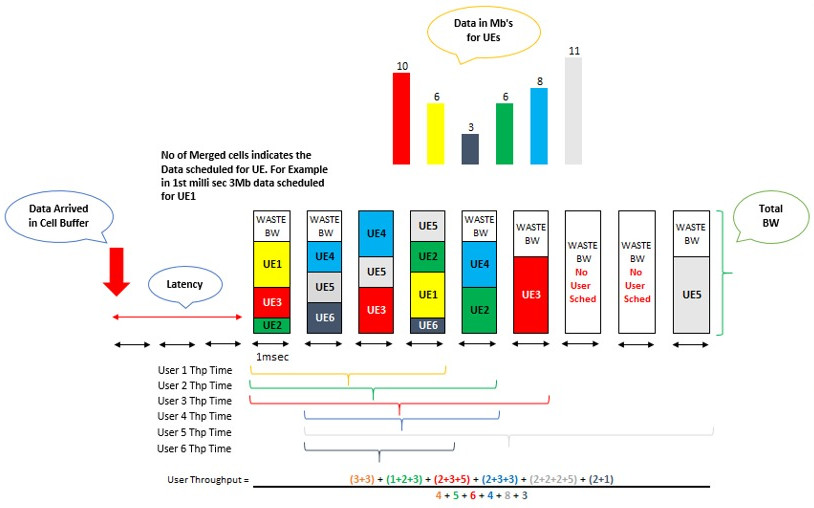
User Throughput like vol/time per qci on which traffic there.
Cell Throughput vol/active tti.
User Throughput calculated to give user experience for Throughput, generally User Throughput on rough side = Cell Throughput / number of active users in cell.
It is importatn to note that User Throughput time starts when first user is scheduled and for Cell Throughput time starts when data arrives in cell DL buffer. So in above case User Throughput = (44 Mega bits / 30 msec ) = 1.46
And Cell Throughput = 44 / 12 = 3.66
This is raw example.
But User Throughput also depends on counter pegging, for example check this figure: