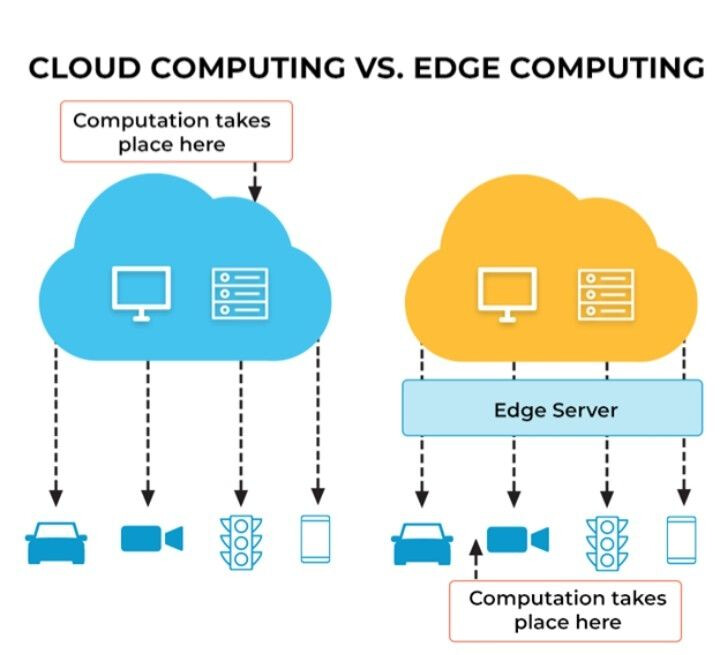
In recent years, the cloud has gone mainstream thanks to its appeal and promise of saving time and money for enterprise organizations. It is one of the most significant forces in today’s enterprise IT environments, bringing improved agility, better scalability, and freeing developers to leave their on-premises hardware. With cloud computing architectures in place, data storage and workload processing have moved to a centralized data center off-premises, typically far away from where the data is accessed.
However, with a growing number of time-sensitive and mission-critical applications, the traditional cloud computing option isn’t always the best option for today’s digital enterprises. To deliver superior customer experiences, businesses are discovering significant benefits by shifting applications to the edge — physically closer to the user or device. With edge resources physically closer to the user, applications can deliver faster response times. By utilizing the power of edge functions, you can rapidly scale your application by pre-processing data at the edge before it hits the origin server, lowering server management costs. The decentralized nature of the edge also makes it possible for more intelligent bot management and security authentication.
Let’s dive into how edge computing works and explore some of its use cases in more detail.
What is cloud computing?
To better understand edge computing, we should first dive a little deeper into how cloud computing works.
A typical cloud computing architecture stores, processes, and analyzes data at a central location (usually the data center). Requests from client applications are routed to the cloud, where they are processed, and results are sent to the device that generated the request.
Cloud computing is delivered through a combination of service and deployment models. Typically, a third party — the provider — manages some or all of it. In a nutshell, the three main cloud computing models are:
-
Infrastructure as a Service (IaaS) - A cloud provider hosts infrastructure components typically part of an on-premises data center, such as servers and storage. Users can access these remotely on an as-needed basis.
-
Platform as a Service (PaaS) - The cloud provider hosts and maintains infrastructure and software on behalf of the user, providing an end-to-end platform for building and running applications. Cloud databases are a form of PaaS.
-
Software as a Service (SaaS) -The cloud provider hosts and maintains software that users may access, typically on a subscription basis.
-
Function as a Service (FaaS) - Cloud providers enable you to run code in response to events without having to worry about deploying infrastructure, building and launching apps.
In recent years, all above models have become increasingly popular since they offer several benefits.
-
Lower CapEx and OpEx Costs: Buying and maintaining hardware is time-consuming and expensive. This responsibility falls on the cloud provider when using a cloud computing model. This minimizes the time, effort, and expense of operating, maintaining, and patching the system, allowing more time for developers to focus on the application development. In addition, the cloud provider performs ongoing maintenance tasks such as applying software patches and upgrades.
-
More choices for the customer: Depending on the cloud model chosen, customers can create their own distributed architectures by stitching together compute instances, load balancers, etc., using IaaS, or go for a more abstracted and packaged implementation using a SaaS service. These choices allow you to get more control over availability, scale and performance for your apps.
Choosing the suitable cloud service model depends on what parts of an application you want to be managed by the cloud provider and what parts you want to handle yourself.
Differences between edge computing and cloud computing
Despite similar concepts behind both computing technologies, there are some key differences, with location being one of the most important.
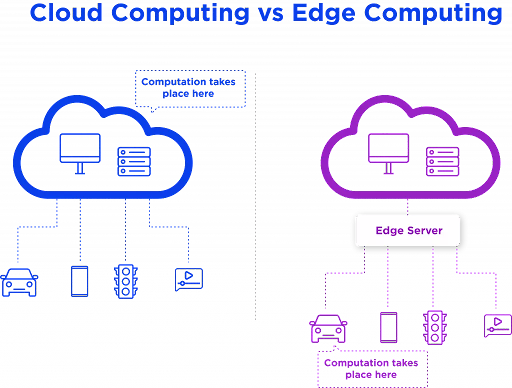
In cloud computing, the hardware used for data storage and processing is located in data centers, distributed globally but centralized in the core of the network. In edge computing, data processing is done closer to the source and a user request is routed over a complex mesh of networking gear including routers, switches, and other equipment, finally hitting a Point of Presence (PoP) along the path. The PoP is located in a physical environment outside of a data center that is intentionally placed as close as possible to the user.
There are two main reasons to move workloads to the edge :
-
Time sensitivity: Latency-sensitive applications need to make decisions very quickly without delay. Data is collected, transferred to a central cloud without modification in cloud computing infrastructures, and processed before a decision is sent back. This process can take some time. If data processing tasks are moved closer to where data is generated, new data requests can be processed at significantly lower latency, and edge devices can cache results for faster data access. This results in enhanced user experiences for various use cases, ranging from connected cars to online gaming.
-
Workloads: Computing, storage, and analytics capabilities once available only in large cloud servers are now possible on devices with a much smaller footprint. With no edge, there would be far too much data to collect to send to a cloud. Edge computing minimizes the need to backhaul data to the cloud.
Edge computing and cloud computing aren’t mutually exclusive. They are built to serve different purposes, but they can serve as the foundation for next-generation applications when combined.
When building these applications from the edge to the cloud, having a good abstraction is critical to enabling computation across heterogeneous resources on the edge and across multiple tiers of resources from the edge to the cloud. Function as a Service can serve as this layer, enabling users to develop, run, and manage applications without having to worry about the complicated infrastructure typically associated with developing and launching an application. These are on-demand functionalities that scale out when there is a heavy load and power down when not in use. They are commonly used across several use cases, including data streaming apps, modern web/mobile applications, and the IoT.
Here are a few benefits of using FaaS in edge environments:
-
Improved performance: In edge environments, FaaS can deliver on-demand content tailored to the user’s environment. If the user is accessing the site on a mobile device, images can be resized on the fly to fit into a mobile browser.
-
Seamless A/B testing: By using FaaS, developers can test and serve different website versions without redirecting or changing the URL using a API gateway layer like OpenFaaS. This allows for continuous improvement of your product with minimal disruptions to the user.
-
Real-time data processing: FaaS can be used to build an analytics platform that tracks and analyzes user behavior in real time.
A serverless database for your next generation cloud solution
In order to realize the full promise of scale, resiliency, and performance that edge computing provides, you need a globally distributed, serverless database that the edge functions can access.
There is a need for a flexible, developer-friendly, transactional database delivered as a secure and scalable cloud API with native GraphQL. Designed to handle the real-time demands of edge computing applications. By combining technologies such as Cloudflare Workers with it you can create an edge app that runs at the edge and delivers results within milliseconds of your users worldwide.
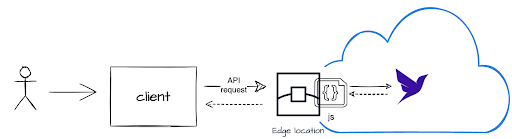
So, for example, if you’re building a streaming content delivery app, the app can subscribe to a document stored in a Fauna database. Any changes to that document are immediately streamed to the app as event notifications. This allows for immediate user interface updates based on activity in your Fauna database.
Source:
https://fauna.com/blog/edge-computing-vs-cloud-computing-whats-the-difference