Artificial Intelligence (AI) chips are purpose-built hardware components designed to accelerate AI workloads, such as model training and inference. This guide explores the key components and architectures involved in modern AI chips, providing a clear overview of their functions and roles.
Key Components & Architectures
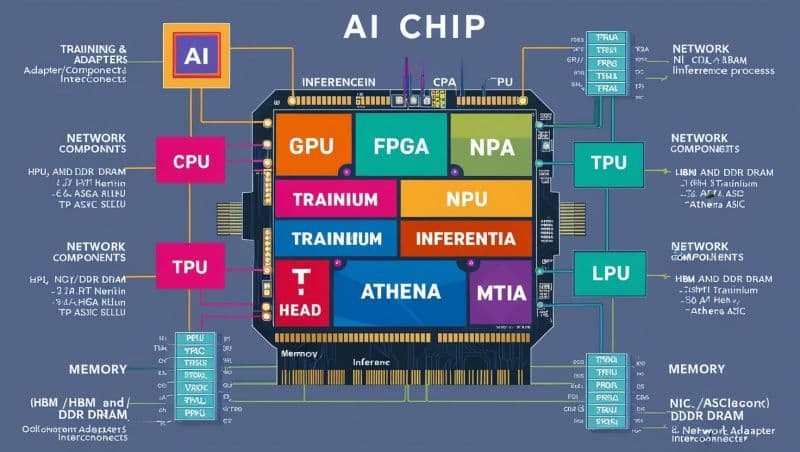
Central Processing Unit (CPU)
While not the primary workhorse for AI, the CPU often acts as the orchestrator. It manages overall system operations, data flow, and less computationally intensive tasks. CPUs may also include components for training coordination and serve as hosts for adapters or interconnects.
Graphics Processing Unit (GPU)
GPUs were among the first to be adapted for AI, thanks to their ability to perform massive parallel processing. They remain essential for demanding AI training tasks and complex inference, particularly in computer vision and large-scale model deployment.
Field-Programmable Gate Array (FPGA)
FPGAs offer reconfigurability and flexibility, making them ideal for tailored hardware acceleration. They are widely used in research, specialized AI applications, and scenarios where adaptability and low latency are critical.
Neural Processing Unit (NPU) / Neural Processing Accelerator (NPA)
These accelerators are designed specifically for AI workloads from the ground up. They excel at executing neural network operations efficiently, delivering higher performance and lower power consumption compared to general-purpose processors. Examples include Amazon’s Trainium and Inferentia, as well as custom ASICs like Athena ASIC.
Tensor Processing Unit (TPU)
Developed by Google, TPUs are application-specific integrated circuits (ASICs) designed to accelerate machine learning workloads using the TensorFlow framework. They are optimized for both training and inference and are a cornerstone of Google’s AI infrastructure.
Language Processing Unit (LPU)
Though not widely adopted, LPUs refer to specialized units aimed at handling Natural Language Processing (NLP) tasks—one of the most prominent and resource-intensive domains in AI.
Specialized AI Cores (e.g., T-Head, Athena, MTIA)
Many chipmakers design proprietary AI cores and architectures optimized for specific workloads or deployment environments. These custom designs can yield significant advantages in power efficiency, latency, and task-specific performance.
Memory Architectures
High Bandwidth Memory (HBM) and DDR DRAM
Memory bandwidth is critical for feeding data to AI processing units, especially during training. HBM and DDR DRAM provide the speed and volume needed to prevent bottlenecks in AI computations.
On-chip Memory
Integrated directly onto the chip, this fast, low-latency memory stores frequently accessed data and intermediate results, reducing reliance on slower external memory and improving performance.
Network-on-Chip (NoC)
A vital component for interconnectivity within the chip, the NoC links processors, memory blocks, and specialized units. It ensures high-speed communication and synchronization across the AI chip’s architecture.
By understanding these core elements, professionals and enthusiasts can better evaluate AI chip technologies and architectures in a rapidly evolving landscape. Whether you’re optimizing models for performance or deploying AI in edge devices, these components define the boundaries of what’s possible.
LinkedIn: ![]()